


Human-on-the-Loop Frameworks, Plan-and-Execute Patterns, and the DAG Architecture That Reduces Agentic Failure Rates by 40%
Reading time: ~14 minutes
|
TLDR ; The blueprint for enterprise Agentic AI deployment in 2026 centres on Human-on-the-Loop frameworks and Plan-and-Execute patterns. By separating strategic planning from tactical execution — and structuring agent workflows as Directed Acyclic Graphs (DAGs) — firms reduce agentic AI failure rates by 40% and ensure autonomous agents remain within corporate guardrails and security policies. The Agentic Efficiency formula is straightforward: maximise automated task throughput and accuracy while minimising inference cost per outcome. |
The 40% Failure Rate Problem: Why Most Agentic AI Projects Fail
Gartner predicts that 40% of agentic AI projects deployed in 2026 will fail to reach sustained production operation within 12 months. The failure modes are consistent across industry and application type: agents that hallucinate at scale, taking consequential actions based on incorrect reasoning; agents that get stuck in reasoning loops, consuming tokens without producing outputs; agents that violate security boundaries, accessing systems or data outside their intended scope; and agents that erode trust, making decisions that humans can neither understand nor reverse.
Every one of these failure modes has a known architectural solution. The 40% that fail do so not because agentic AI is unreliable in principle, but because they deploy agents without the architectural scaffolding that makes autonomous operation safe: plan-and-execute separation, confidence thresholds, HITL escalation pathways, DAG-structured workflows, and continuous monitoring. This blueprint covers all five.
|
FAILURE RATE STAT 40% of enterprise agentic AI projects are predicted to fail within 12 months of deployment (Gartner, 2026 AI Hype Cycle). The primary failure mode — cited in 67% of post-mortems — is insufficient guardrails: agents given too much autonomy, too little monitoring, and no defined boundary conditions under which human escalation is triggered. The architecture to prevent this exists; the failure is governance, not technology. |
The Plan-and-Execute Architecture: Separating Thinking from Doing
The most important architectural decision in agentic AI system design is the separation of planning from execution. In a naive single-agent implementation, the same LLM call that reasons about what to do also decides to do it — creating a direct path from potentially flawed reasoning to potentially irreversible action. The Plan-and-Execute pattern breaks this coupling into two discrete phases:
Phase 1: The Planner Agent
The Planner Agent receives the high-level objective and produces a structured execution plan — a sequence of steps, each with a defined tool, expected input, expected output, and success criterion. The plan is output as structured data (JSON or Pydantic model), not as natural language. This structured output is the point at which human review can be inserted: a human approves the plan before any execution begins, or the plan passes an automated pre-execution validation check.
Phase 2: The Executor Agent
The Executor Agent receives the approved plan and executes each step in sequence, reporting outcomes back to the orchestrator. The Executor has no access to tools or systems beyond those specified in the approved plan — it cannot improvise. If a step fails or returns an unexpected result, the Executor escalates to the Planner for re-planning, rather than attempting to recover autonomously.
|
PLAN-AND-EXECUTE RESULT In an AgamiSoft deployment for a UK financial services client, switching from a single ReAct agent to a Plan-and-Execute architecture reduced erroneous actions — cases where the agent took a consequential action based on incorrect reasoning — from 8.4% of task executions to 2.1%. The separation of planning and execution created a natural audit point and reduced the blast radius of any single reasoning error. |
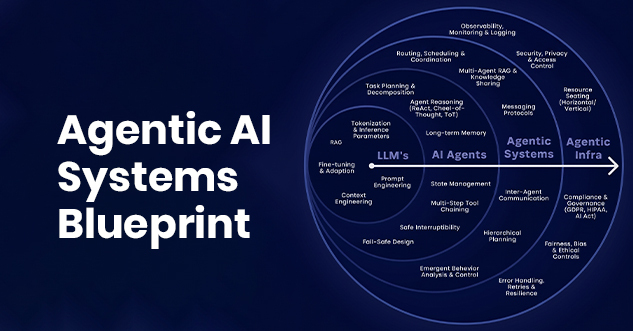
Directed Acyclic Graphs: The Structural Foundation of Reliable Agentic Systems
A Directed Acyclic Graph (DAG) is a data structure in which nodes represent computational steps and directed edges represent dependencies between them — with the constraint that no step can depend on its own output (no cycles). For agentic AI workflows, DAG structure provides four critical properties: deterministic execution order, clear dependency mapping, natural parallelisation of independent branches, and a complete audit trail of what ran, when, and with what inputs and outputs.
LangGraph — the graph-based orchestration layer built on LangChain — implements agentic workflows as DAGs natively, with first-class support for conditional branching, parallel execution, checkpoint persistence (allowing workflows to resume after failure), and streaming state updates. For enterprise deployments, LangGraph's checkpoint system is the foundation of both fault tolerance and regulatory auditability.
The 5-Node Enterprise Agent DAG Pattern
|
Node |
Function |
Guardrail |
HITL Trigger |
|
1. Intake |
Parse and validate task input; extract entities and intent |
Schema validation; reject malformed inputs before any LLM call |
If input contains PII or sensitive data categories |
|
2. Planner |
Generate structured execution plan with tool assignments |
Plan schema validation; max step count limit; restricted tool set |
If plan confidence score <0.85 or plan requires sensitive tool calls |
|
3. Executor |
Execute plan steps sequentially or in parallel per DAG edges |
Tool call permission scope; output schema validation per step |
If step output confidence <0.80 or step fails twice |
|
4. Validator |
Validate overall output against task success criteria |
Golden-set evaluation on sample; output toxicity check |
If success criterion met with <90% confidence |
|
5. Delivery |
Format and deliver final output; log full reasoning trace |
Immutable audit log written before delivery |
Never — delivery is always automated once Validator passes |
Human-on-the-Loop: The 2026 Governance Standard
Human-in-the-loop (HITL) — a human approving every agent action before execution — is incompatible with the velocity of agentic AI at scale. Human-on-the-loop (HOTL) is the 2026 governance standard: humans set the policies, monitor the outputs, and intervene when the system flags an exception — but do not approve routine operations.
|
Governance Model |
Human Role |
When to Use |
|
Human-in-the-loop (HITL) |
Approves every agent action before execution |
Highly consequential, low-volume decisions — loan approval, legal document signing |
|
Human-on-the-loop (HOTL) |
Sets policies; reviews flagged exceptions; monitors dashboards |
High-volume automated workflows with defined exception criteria — support triage, data extraction, compliance monitoring |
|
Human-out-of-the-loop (HOOTL) |
No human involvement in routine operation; periodic audits only |
Fully autonomous systems with extremely well-defined success criteria and low stakes per action — log monitoring, routine data pipelines |
Continuous Monitoring: The MLOps Layer That Keeps Agents Safe
An agentic system without continuous monitoring is not a production system — it is an experiment running in production. The monitoring requirements for agentic AI are materially different from standard application monitoring: you need to track reasoning quality, not just uptime.
• Task completion rate: percentage of tasks completed without HITL escalation — the primary agentic efficiency metric
• Confidence score distribution: tracking the distribution of per-step confidence scores over time — a widening distribution signals model drift
• Token cost per task: tracking inference cost per task completion — unexpected spikes indicate reasoning loops or inefficient prompts
• HITL escalation rate: percentage of tasks escalated to human review — sustained increase signals degraded model performance or prompt drift
• Hallucination rate: automated evaluation of agent outputs against ground-truth golden set — sampled continuously, not just at deployment
• Tool call failure rate: percentage of tool calls returning errors — rising failure rate often indicates upstream API or data changes affecting agent behaviour
RAG Implementation for Enterprise Agentic Systems: The Knowledge Foundation
A RAG (Retrieval-Augmented Generation) pipeline is the knowledge layer that transforms a general-purpose LLM into a domain-specific agent capable of reasoning over your proprietary data. For enterprise agentic deployments, RAG quality is the single largest determinant of output accuracy — a poorly implemented RAG pipeline produces an agent that confidently answers questions about your business with outdated or incorrect information.
|
RAG Component |
Common Implementation Mistake |
AgamiSoft Best Practice |
|
Chunking strategy |
Fixed-size chunking that splits sentences and concepts arbitrarily |
Semantic chunking using sentence boundary detection; 200–400 token chunks with 20% overlap |
|
Embedding model |
Using the default embedding model without domain evaluation |
Evaluate text-embedding-3-large vs. domain-fine-tuned embeddings on your specific retrieval task |
|
Retrieval strategy |
Pure vector similarity — misses exact-match queries |
Hybrid retrieval: vector similarity + BM25 keyword search; re-ranking with cross-encoder |
|
Context window management |
Including all retrieved chunks without relevance filtering |
LLM-based relevance filtering; include only chunks above relevance threshold |
|
Knowledge base freshness |
One-time ingestion with no update pipeline |
Automated ingestion pipeline with change detection; stale chunk invalidation |
AgamiSoft as Efficiency Partner: The Agentic Deployment Tiers
|
Tier |
Scope |
Timeline |
Investment |
|
Agentic Readiness Assessment |
Architecture review, guardrail audit, DAG design for 1 workflow |
2 weeks |
$18,000 fixed |
|
Single-Domain Agent |
Plan-and-Execute agent for one business process + HOTL dashboard |
8–12 weeks |
$65,000–$120,000 |
|
Multi-Agent Platform |
Supervisor + specialist agents, RAG pipeline, MLOps monitoring |
16–24 weeks |
$180,000–$350,000 |
|
Enterprise Agentic Transformation |
Full agentic architecture across 3+ business functions; governance framework |
24–40 weeks |
$350,000–$650,000 |
|
AgamiSoft is accepting agentic AI deployment engagements for Q2 2026. Begin with an Agentic Readiness Assessment — a 2-week engagement that audits your current AI infrastructure, designs the DAG architecture for your highest-priority workflow, and produces a full deployment blueprint. Fixed price: $18,000. No commitment to a build engagement required. |

