Trusted by UNICEF & 50+ Global Company
From startups to enterprises — deliver scalable, secure solutions backed by 8+ years of expertise and ISO 9001-certified standards.
We've done 200+ enterprise and
business consulting









Delivering innovative solutions and advanced technologies tailored to drive sustainable business growth.
Delivering innovative solutions and advanced technologies tailored to drive sustainable business growth.
Our Certifications & Reviews
Our Certifications & Reviews
Transforming businesses with intelligent AI solutions and automated workflows









Creating scalable, secure and high-performance digital products









Helping businesses grow through data-driven digital strategies






A transparent and collaborative process that ensures quality predictable outcomes throughout every project lifecycle.

How We Automated Cancer Drug Manufacturing with GAMP4-Compliant.

Designing scalable architectures through iterative prototyping and validation.

Rigorous development and testing cycles ensuring quality deliverables.

Seamless deployment and ongoing support for long-term success.
Leveraging modern frameworks, cloud platforms, and AI technologies to build secure, scalable, and future-ready digital products.
 React
React
 Vue.js
Vue.js
 Angular
Angular
 Next.js
Next.js
 TypeScript
TypeScript
 Tailwind CSS
Tailwind CSS
 HTML5
HTML5
 CSS3
React
Vue.js
Angular
Next.js
TypeScript
Tailwind CSS
HTML5
CSS3
CSS3
React
Vue.js
Angular
Next.js
TypeScript
Tailwind CSS
HTML5
CSS3
 SASS
SASS
 JavaScript
JavaScript
 Node.js
Node.js
 Python
Python
 PHP
PHP
 Laravel
Laravel
 Django
Django
 Express.js
SASS
JavaScript
Node.js
Python
PHP
Laravel
Django
Express.js
Express.js
SASS
JavaScript
Node.js
Python
PHP
Laravel
Django
Express.js
 Java
Java
 Spring Boot
Spring Boot
 Go
Go
 Rust
React Native
Rust
React Native
 Flutter
Flutter
 Swift
Swift
 Kotlin
Java
Spring Boot
Go
Rust
React Native
Flutter
Swift
Kotlin
Kotlin
Java
Spring Boot
Go
Rust
React Native
Flutter
Swift
Kotlin
A transparent and collaborative process that ensures quality predictable outcomes throughout every project lifecycle.

LMS solutions built with Moodle: live reporting to live reporting to
LMS solutions built with Moodle: live reporting to live reporting to
LMS solutions built with Moodle: live reporting to live reporting to
LMS solutions built with Moodle: live reporting to live reporting to
LMS solutions built with Moodle: live reporting to live reporting to
Why Choose us
Connect your systems effortlessly with modern.
Successful digital projects delivered globally for startups.

Delivering scalable software solutions worldwide
Senior-led development squads engineered exclusively.





Join a team of innovators, engineers, and problem-solvers creating impactful software solutions that help businesses grow and transform digitally.

Working with AgamiSoft was seamless from start to finish. The final product improved our efficiency and customer experience significantly."
AgamiSoft specializes in custom software development, mobile app development, web applications, cloud solutions, and digital transformation services. We work with businesses across various industries to build scalable, secure, and innovative technology solutions.
Yes. AgamiSoft holds ISO 9001 certification for Quality Management and ISO 27001 certification for Information Security Management. Both certifications are independently audited and renewed annually.
Yes, AgamiSoft is ISO 9001:2015 certified for Quality Management Systems and ISO 27001:2013 certified for Information Security Management.
We serve healthcare, fintech, e-commerce, education, logistics, manufacturing, and enterprise sectors across startups, SMEs, and large enterprises.
We follow rigorous QA processes including automated testing, manual testing, code reviews, continuous integration/deployment, and adherence to industry best practices.
Absolutely. We have extensive experience integrating with payment gateways, CRM systems, ERP platforms, marketing tools, analytics services, and various APIs.


The blog introduces AgamiSoft’s 7-Day AI Code Cleanup Proof of Concept (PoC), a fixed-fee engagement that remediates t...
Read More
The blog explains how UK SMEs in 2026 can achieve 45% cost reduction and overcome the post-Brexit tech talent shortage b...
Read More
The blog explains how cloud-native migration in 2026 has evolved from simple Lift-and-Shift to event-driven orchestratio...
Read More
The blog explains how next-generation healthcare ERP platforms in 2026 address two critical imperatives: reducing clinic...
Read More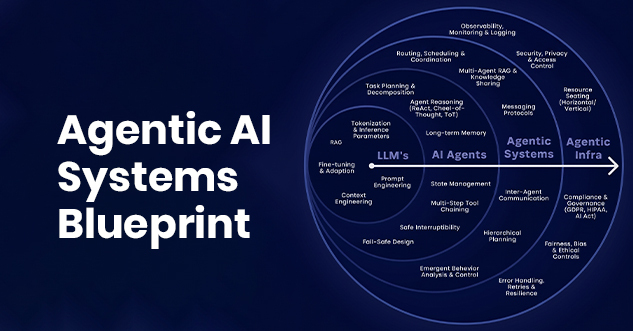
The blog explains how enterprises in 2026 can reduce agentic AI failure rates by 40% through structured architectures. I...
Read More
The blog presents original research on GCC digital transformation, highlighting a $71.64 billion market in 2026 driven b...
Read More



